Scaling Law of LLM Hallucination
Understanding why Large Language Models (LLMs) sometimes ‘hallucinate’—generating fluent but factually incorrect or nonsensical information—is an important challenge. While a complete picture remains elusive, we can construct theoretical models to gain insights. These models allow us to explore how the propensity for hallucination might scale with factors like the volume of training data, the inherent complexity of language, and the way we ask models to generate text. This post delves into one such mathematical exploration. We’ll derive, from a set of foundational assumptions, a lower bound on hallucination probability and examine how this bound is governed by these critical parameters.
Core Concepts and Notation
We begin by defining the essential components and notation used throughout this derivation.
An LLM with parameters models a conditional probability distribution , where is the input context of length , and is the next token. The model outputs logits , where is the logit for the -th token in a vocabulary of size .
The probability of generating a specific token given context is given by the softmax function applied to the logits:
When generating text with a temperature parameter , this probability is adjusted:
A lower temperature () makes the distribution sharper (more deterministic), while a higher temperature () makes it flatter (more random).
For a given context , let denote the “correct” or desired next token (e.g., in factual recall tasks where the answer is unambiguous). The hallucination probability is then the probability of not generating this correct token:
Our goal is to understand how , the average hallucination probability over all contexts, behaves.
Modeling Logits from Corpus Evidence
Our first step is to model how an LLM might arrive at its logits based on its training data. One way to approach this is by considering the behavior of very wide neural networks, a regime often studied through the Neural Tangent Kernel (NTK). In the NTK limit, particularly for networks trained with gradient descent, the output of the network (e.g., a logit for a specific token) can be approximated as a linear function of the initial parameters.
Equivalently, this can be viewed as a sum over contributions from the training data, weighted by the NTK. Specifically, the logit for a token given a context , after training on a corpus , can be expressed in a form like:
Here, is the Neural Tangent Kernel evaluated between the current context and a training context (computed with network parameters at initialization ). The terms are learned coefficients that depend on the specific training example (including the target token and its relation to ), and is a bias term.
This formulation suggests that logits are built by accumulating “support” from similar training instances.
For simplicity and tractability in our analysis, we adopt a simplified model inspired by this NTK perspective. We propose that the logit for a token given context is primarily determined by how much “support” in the corpus favors in this context, versus the total support for any token. The logit is approximated as:
In this model:
-
represents the accumulated support for token in the context , which we can also refer to as its “evidence density”. It is calculated by summing a semantic similarity kernel, , over all training instances from the corpus where the target token was indeed . The kernel measures the relevance of a training context to the current context , with . Formally:
Intuitively, the more ‘support’ (high-similarity training examples) the model has seen for following a context like , the higher its evidence density will be. This quantity is bounded by , where is the total count of token in the training corpus.
-
represents the total support for any token in the context . It is the sum of the individual evidence densities for all possible tokens in the vocabulary :
This can also be expressed as a sum of kernel similarities over all training examples whose contexts are relevant to the current context , regardless of the target token: . Consequently, , the total size of the training corpus.
-
and are parameters that scale the influence of these respective support terms, and is a constant bias term.
This simplified model captures a competitive dynamic: a token gains logit strength proportional to its specific support , but this is counteracted by the total support for all tokens in that context. Essentially, a token’s logit is determined by its own support, penalized by a measure of the ‘background’ support for all tokens in that context. This form, while simplified, allows for a more tractable analysis of hallucination probability.
Condition for Bounded Hallucination
Now, let’s consider what it takes for the hallucination probability for a specific context to be below a chosen threshold . If , then the probability of generating the correct token must be .
This implies that the logit of the correct token must be sufficiently larger than the logit of any other token . For the highest-logit alternative token , and assuming a large vocabulary , this condition can be shown to require:
Substituting our simplified logit model into this inequality, we get a condition on the difference in evidence densities:
Let’s define the right-hand side as . This term represents the minimum evidence advantage the correct token must have over its strongest competitor. If , then .
In simpler terms, for the model to avoid hallucinating (with probability at least ) in a given instance, the ‘evidence signal’ for the correct token must exceed the evidence for the strongest competitor by this margin . This margin depends on our desired confidence (related to ) and the generation temperature . A higher temperature or a stricter (smaller) demands a larger evidence gap.
Aggregate Hallucination and Data Sparsity
Deriving the exact average hallucination probability is complex. Instead, we seek a lower bound. To make progress, we consider a simplified (and stronger) condition for when : we assume this happens if the total evidence density for the context, , is less than the required evidence margin .
The intuition is that if the overall evidence available for any token in a given context is very low (i.e., the context is highly unfamiliar or ambiguous based on the training data, such that ), it becomes difficult for the correct token to gather enough evidence to significantly surpass alternatives by the necessary margin. This simplification allows us to use aggregate statistics of to derive a bound.
1. Average Total Evidence: The average total evidence density, , taken over all possible contexts (assuming a uniform distribution over a context space of size ), is:
Where:
- is the size of the training corpus.
- is the average kernel influence (effectively, how many contexts are ‘covered’ by an average training example ).
- approximates the size of the unique context space. This shows that average evidence density increases with corpus size and decreases with the vastness of the language space.
2. Lower Bound on Fraction of Low-Evidence Contexts: Let be the fraction of contexts for which . For these contexts, by our simplifying assumption, . Using Markov’s inequality, which states for a non-negative random variable , we have . Therefore, the fraction of low-evidence contexts is bounded:
This bound is informative (i.e., ) if .
Let . This term increases as gets closer to 0 or 1, reflecting a demand for a larger logit gap. Let be a constant that groups model structure and kernel properties. The ratio then becomes . So, the lower bound on is:
3. Lower Bound on Average Hallucination: The average hallucination probability can be lower-bounded because, for the fraction of contexts, and thus .
Substituting the bound for gives
This inequality is a lower bound on the average hallucination probability. Let’s break down the term :
- represents the ‘total effective evidence’ in the corpus, scaled by model and kernel parameters.
- is the vastness of the potential context space.
- represents the ‘difficulty’ of distinguishing the correct token, influenced by temperature and our chosen hallucination threshold .
If this ratio (representing data richness relative to task difficulty for a given ) is small (i.e., ), the term in the parenthesis approaches 1, and the bound approaches . If is large, the bound can become smaller. This expression already hints at the scaling relationships we’re looking for, but it still depends on our arbitrary choice of .
Optimizing the Lower Bound
The derived lower bound depends on our choice of . We can find the tightest possible bound by choosing to maximize . Let be the key scaling parameter, which encapsulates data density (), model characteristics (), and inverse temperature (). The bound is .
The optimal that maximizes (where is the optimal threshold) is found by solving the following transcendental equation:
While this equation doesn’t have a simple closed-form solution for , its properties can be analyzed, especially in asymptotic regimes (when is very small or very large). This represents an optimal ‘logit difference scale’ that balances making small (desirable for the factor in the bound) versus making the term large.
The optimized value is then . Substituting and into gives the optimized lower bound on average hallucination:
This is our main result: a lower bound on average hallucination probability that depends on the consolidated parameter .
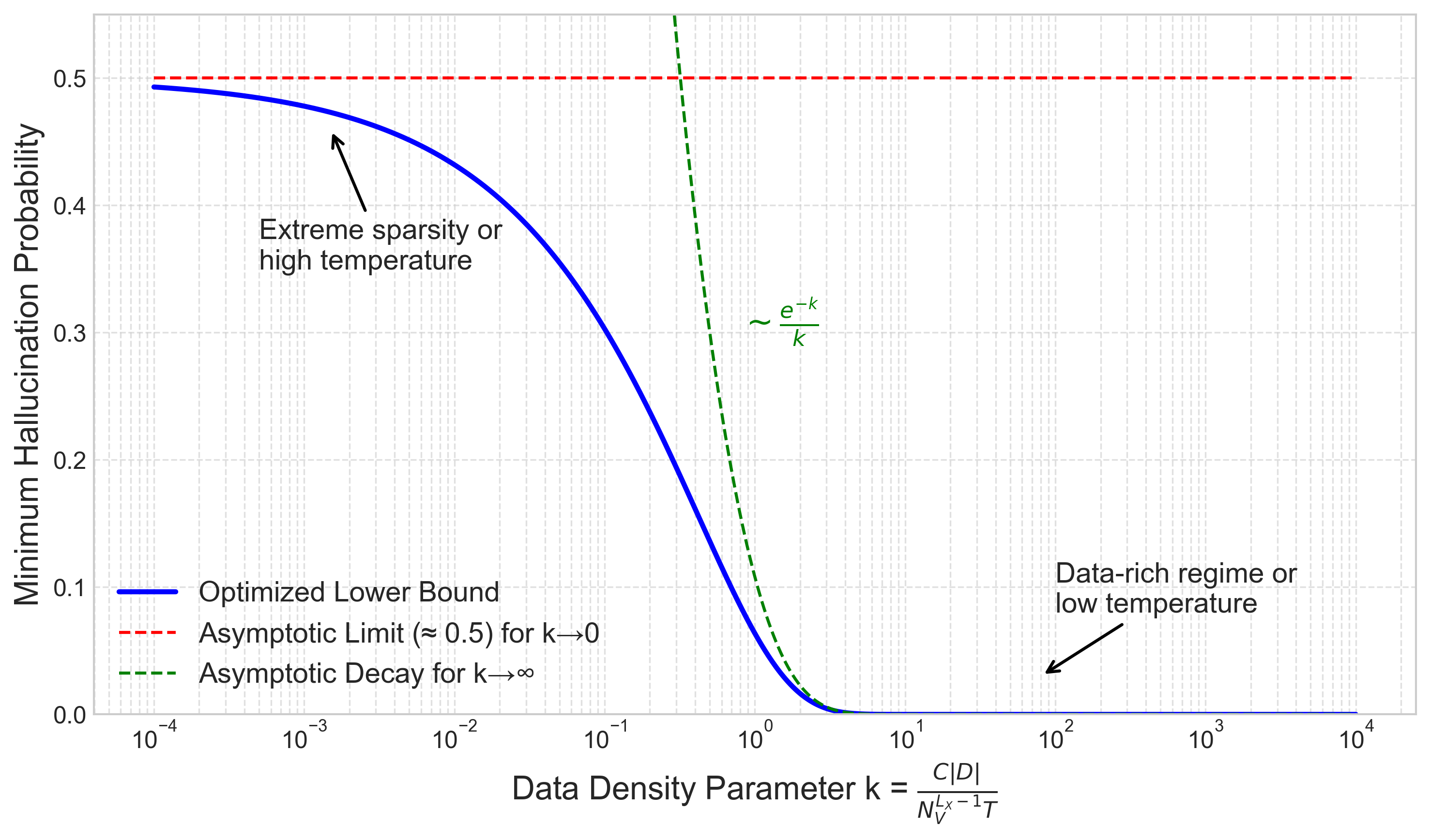 Figure 1: The optimized lower bound on average hallucination probability, , as a function of the data density, model, and temperature parameter . The bound transitions from for small (sparse data/high temperature) towards for large (dense data/low temperature).
Figure 1: The optimized lower bound on average hallucination probability, , as a function of the data density, model, and temperature parameter . The bound transitions from for small (sparse data/high temperature) towards for large (dense data/low temperature).
We can derive the behavior of this optimized bound in limiting cases of the parameter :
-
(Extreme Data Sparsity or High Temperature) In this regime, data is very scarce relative to language complexity, or generation is very random. It can be shown that , which approaches 0. As , . Further analysis shows the entire bound . This suggests that with very sparse data or at very high temperatures, the model’s output is nearly random concerning correctness, leading to an average hallucination probability of at least 50%. This makes intuitive sense: if the model has very little reliable information from its training (), its performance should degrade towards random guessing. For a binary decision of ‘correct’ vs ‘any incorrect alternative’, random guessing would yield a 50% error rate.
-
(Data-Rich Regime or Low Temperature) In this regime, data is abundant, or generation is nearly deterministic. It can be shown that . Then . The term approaches 0. More precisely, the bound decays towards 0, approximately as . This indicates that with sufficiently dense data and low temperature, the derived lower bound on hallucination can be made arbitrarily small, decaying exponentially with . This is also intuitive: if we have abundant data relative to complexity and low randomness (), the model should be able to learn the correct patterns effectively, and the floor for hallucination should drop significantly.
Conclusion
This derivation provides a theoretical lower bound on the average hallucination probability in LLMs, starting from a model of how corpus evidence translates to logits. It formally demonstrates how this hallucination floor scales with fundamental parameters, encapsulated in the parameter :
- Corpus Size (): Larger datasets tend to decrease the bound (increase ).
- Context Space Complexity (): Larger vocabularies or longer contexts increase complexity and tend to increase the bound (decrease ).
- Generation Temperature (): Higher temperatures tend to increase the bound (decrease ).
- Model/Kernel Properties (): Factors like effective semantic similarity spread also play a role.
It is important to remember that this model, while illustrative, is a significant simplification of the complex mechanisms underlying LLM behavior, and does not encompass more intricate forms of hallucination. Note that the exact form of the scaling we derived here is predicated on the softmax function. A natural follow-up question is whether there is an alternative to softmax that would result in qualitatively better scaling behavior.