Why Some Puzzles Are Hard for LLMs: A Framework for Cognitive Load
As Large Language Models (LLMs) get better at complex reasoning, we need better ways to measure the difficulty of the tasks we give them. A fascinating paper from researchers at Apple, “The Illusion of Thinking”, systematically tested models like Claude 3.7 Sonnet on various puzzles. They measured complexity using straightforward metrics like the problem size () or the number of moves in the solution.
Their findings revealed an interesting inconsistency: models could solve a Tower of Hanoi puzzle requiring over 100 moves, yet fail on a River Crossing puzzle that needs only a dozen. This suggests that simple metrics like “number of moves” don’t provide a universal measure of difficulty. Different puzzles stress a model’s capabilities in different ways.
This post introduces a framework to normalize the concept of task difficulty into a single, unified metric: Cognitive Load (). By defining difficulty in terms of the underlying computational work a model must perform, we can explain why some seemingly simple problems are incredibly hard for LLMs and predict when their performance will start to degrade.
A Look at the Puzzles
To understand how cognitive load is calculated, it helps to first understand the mechanics of the puzzles used as benchmarks.
Tower of Hanoi
This puzzle features three pegs and disks of different sizes stacked on the first peg in size order (largest at bottom). The goal is to transfer all disks from the first peg to the third peg. Valid moves include moving only one disk at a time, taking only the top disk from a peg, and never placing a larger disk on top of a smaller one. The difficulty can be controlled by the number of initial disks; the minimum number of required moves with disks is .
Checker Jumping
This is a one-dimensional puzzle with red checkers, blue checkers, and a single empty space in a line. The objective is to swap the positions of all red and blue checkers, mirroring the initial configuration. Valid moves include sliding a checker into an adjacent empty space or jumping over exactly one checker of the opposite color to land in an empty space. Checkers cannot move backward. The complexity is controlled by the number of checkers: with checkers (n of each color), the minimum number of moves is .
River Crossing
This is a constraint satisfaction puzzle involving “actors” and their corresponding “agents” who must cross a river in a boat. The goal is to transport all individuals from one bank to the other. The boat has a limited capacity () and cannot travel empty. The core constraint is that an actor cannot be in the presence of another’s agent unless their own agent is also present. For and n=3, the boat capacity is , and for larger , .
Blocks World
This block-stacking puzzle requires rearranging blocks from an initial configuration to a specified goal state. The objective is to find the minimum number of moves. Valid moves are restricted to the topmost block of any stack, which can be placed either on an empty space to start a new stack or on top of another block. The complexity is controlled by the number of blocks. While part of the original study, this puzzle was excluded from our main analysis due to its stochastic nature, which introduces significant noise into the performance data.
The Cognitive Load Framework
To create a single, unified metric for reasoning difficulty, we must start from a fundamental principle of computational work. The “true” cognitive load of a task is the sum of the work done at every deliberative step of its solution. The work at each step depends on the complexity of the rules being applied () and the size of the state information () relevant at that specific step.
While this summation represents the ground truth, it can be unnecessarily complex to calculate. We therefore propose a more practical and operational model that approximates this work:
In this formula, is the peak state complexity encountered, is the constant constraint complexity, and is a scaling factor that characterizes the structure of the algorithm’s solution path. The power of this model is that it generalizes well across different types of algorithms, as we will now show.
The Three Components of the Model
1. State Information Density ()
This component quantifies the maximum working memory required at any single point during the problem-solving process.
Definition: The State Information Density, , is the Shannon entropy of the largest state space the model must consider to execute its algorithm for instance .
2. Constraint Complexity ()
This component quantifies the complexity of the puzzle’s ruleset.
Definition: The Constraint Complexity, , is the number of fundamental, atomic logical or relational predicates required to express the algorithm that validates a single move.
3. Solution Path Complexity ()
This is a structural scaling factor that depends on the class of algorithm used to solve the puzzle. It accounts for how the state information changes over the course of the solution.
Case A: Iterative Algorithms
- Examples: River Crossing, Checker Jumping.
- Method: These problems are solved by exploring a state-space graph one step at a time. The relevant state information, , is constant throughout this search and is equal to .
- Justification: The true work sum becomes . Our model, , is therefore an exact representation if we define as the number of steps in the solution path.
- Calculation of : is the length of the shortest known solution path, .
Case B: Recursive Algorithms
- Example: Tower of Hanoi.
- Method: These problems are solved by breaking them down into smaller sub-problems. The state information the model must focus on, , is smaller for the sub-problems than for the main problem. The “true work” sum resolves to be proportional to .
- Justification: Our model uses (the state of the full n-disk problem) and a scaling factor . For to match the true scaling, must be proportional to . This corresponds perfectly to the algorithm’s recursion depth. Our model is thus a well-justified approximation that correctly captures the problem’s scaling behavior.
- Calculation of : is the maximum recursion depth of the algorithm.
The Cognitive Load Formula
The final formula provides a concrete method for calculating a single, unified difficulty score for any discrete reasoning task.
Case Studies: The Framework in Action
Let’s apply this formula to the three puzzles mentioned earlier to see how it works in practice.
Case Study 1: Tower of Hanoi
-
State (): For disks and 3 pegs, there are configurations.
-
Constraints (): A move is valid if: 1) the source disk is the top of its peg, AND 2) the destination peg is either empty OR its top disk is larger. This requires 3 atomic predicates.
-
Path (): The solution is recursive, and the number of cognitive steps corresponds to the recursion depth.
-
Cognitive Load ():
Case Study 2: Checker Jumping
-
State (): The number of states for squares grows such that the log-information is approximately .
-
Constraints (): The rules for valid moves (slides, jumps, directionality) are complex, requiring approximately 8 atomic predicates to define.
-
Path (): The puzzle requires planning to avoid dead ends, with a cognitive path length proportional to the minimum solution length.
-
Cognitive Load ():
Case Study 3: River Crossing
-
State (): With pairs of agents, the state is defined by the location of individuals and the boat.
-
Constraints (): The safety condition must be checked for all actors on both banks, which involves checking pairs of actors. The complexity grows quadratically.
-
Path (): Solving requires a state-space search, and the path length is the number of steps in the shortest solution, .
-
Cognitive Load ():
Unified Performance Curve
The Apple paper provides accuracy data for Claude 3.7 Sonnet across these puzzles. When we re-analyze their data, not against problem size but against our calculated Cognitive Load, something remarkable happens. The performance data from all these different puzzles, which looked inconsistent before, now collapses onto a single, predictable curve.
By fitting a single sigmoid function (which describes a sharp transition) to the combined data from both puzzles, we can identify a unified critical threshold. The fit gives a consistent critical load of .
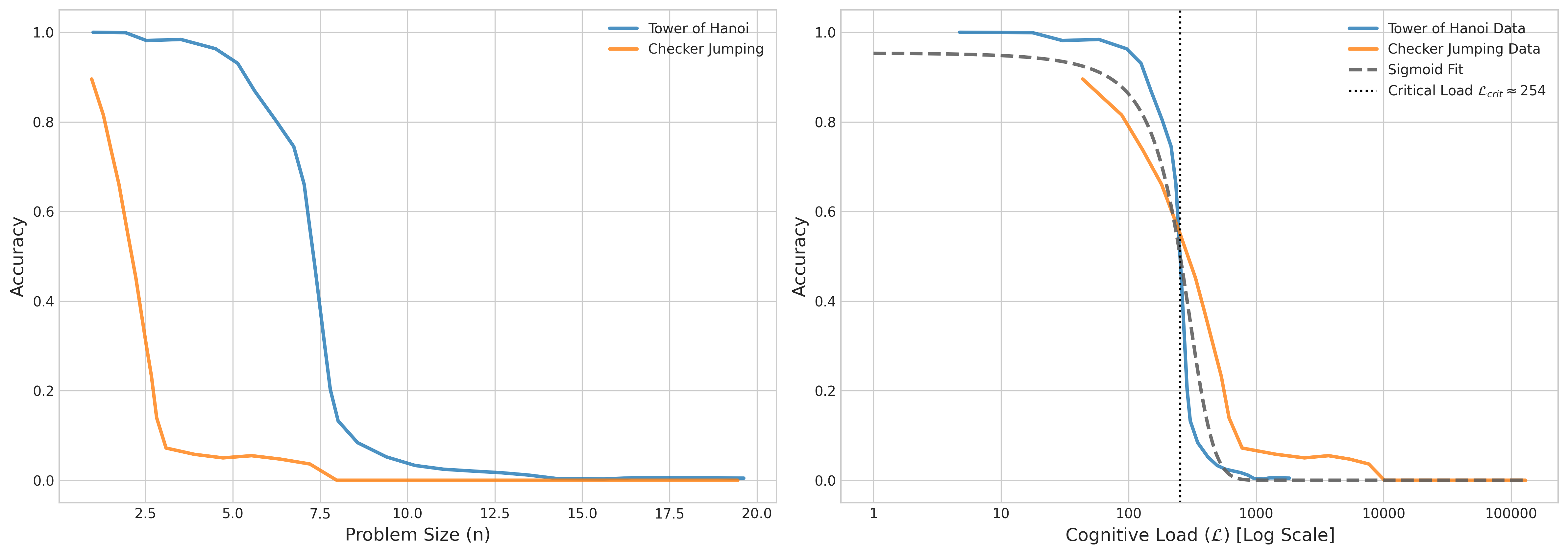 Figure 1: Side-by-side comparison of Claude 3.7 Sonnet’s performance. Left: Plotting accuracy against problem size shows two completely different performance curves. Right: Plotting accuracy against the unified Cognitive Load () metric aligns the data from both puzzles onto a single curve. The grey dashed line shows a single sigmoid curve fitted to all data points, revealing a consistent critical threshold of ~254.
Figure 1: Side-by-side comparison of Claude 3.7 Sonnet’s performance. Left: Plotting accuracy against problem size shows two completely different performance curves. Right: Plotting accuracy against the unified Cognitive Load () metric aligns the data from both puzzles onto a single curve. The grey dashed line shows a single sigmoid curve fitted to all data points, revealing a consistent critical threshold of ~254.
This curve reveals a unified critical load threshold () for the model. Based on our analysis of the published data, this threshold for Claude 3.7 Sonnet appears to be around .
This threshold acts as a fundamental constraint on the model’s reasoning capacity.
Predicting Performance: A River Crossing Case Study
The true power of this framework lies not just in explaining performance but in predicting it. We can test this by applying the Cognitive Load formula to the River Crossing problem. The Apple paper reports a sharp performance drop for Claude 3.7 Sonnet on this specific puzzle: from ~80% accuracy for the case down to 0% for . Let’s see if our model predicts this cliff.
- Case 1: River Crossing with n=2 (2 pairs, optimal solution has 5 moves)
- Cognitive Load:
- This load is well below the critical threshold of ~254, correctly predicting a high likelihood of success.
- Case 2: River Crossing with n=3 (3 pairs, optimal solution has 11 moves)
- Cognitive Load:
- This load is nearly four times the critical threshold, correctly predicting catastrophic failure.
The framework’s predictions align perfectly with the observed results. The model succeeds when the task is below its cognitive limit and fails when the task exceeds it. This demonstrates how Cognitive Load provides a more robust and predictive measure of task difficulty than simple metrics like the number of moves. This also helps explain the paper’s finding that models’ reasoning effort (measured in token usage) declines at high complexity; once the cognitive load is past the critical threshold, the model effectively gives up.
Conclusion
The Cognitive Load framework provides a structured way to think about and quantify the difficulty of reasoning tasks for LLMs. By breaking down the problem into State, Constraint, and Path complexity, we get a metric that is both theoretically sound and seems to work in practice when applied to existing research data.